


Big Brain, Small Phone - A.I. for Dominion
Developing an AI Opponent for board game apps

Artificial intelligence is exploding right now. ChatGPT, Dall-E, and others are demonstrating the power of large learning models. But similar models can also be used for more focused projects, like creating a robust AI opponent for the mobile version of a board game.
While I know the basics of how AI operates, I am far from an expert in this field. So I am very excited to turn over this issue to someone who is an expert - Theresa Duringer.
Theresa is owner and CEO of Temple Gates Games, a digital boardgame development studio based out of San Francisco. Her team is known for digitizing Dominion, Race for the Galaxy, Roll for the Galaxy, and Ascension. Her company's focus is in scaling AI across games with several expansions, including those yet to be designed, through reinforcement learning. Before launching into digital boardgames, she worked on Spore, Sim City, and the Sims at Maxis.
So without further ado, here is Theresa’s deep dive into reinforcement learning.
The Puzzle
Most players play digital boardgames against an AI. It’s a way to learn a new game in a safe, unjudging environment, and it’s a way to investigate the space of the design at their own pace. If done right, an AI can challenge a player, no matter their skill level.
The best AIs excel through learning, but practical applications of reinforcement learning for gaming AI have been elusive. While theoretically an AI can play against itself to learn and grow, there have been little to no examples of this working successfully in production, prior to our title, Race for the Galaxy.
The research project, AlphaStar was created to play StarCraft, and can beat top players at the game. However, AlphaStar is specialized for specific maps with specific races. Game studios need AI that generalize to all opponent styles in all levels or scenarios for shipping products. Would it be possible to use the ideas behind Google’s AlphaZero, which successfully created an effective AI for chess and Go running on supercomputers, and apply them to a shipping product, Dominion, running on phones?
Our Evolution
To understand the problem, it helps to understand our AI research evolution. When we started making digital boardgames, we used the industry standard method of creating a utility AI. This AI is hand scripted to look at a scenario, and follow the condition based rules the developer has laid out. If player A has X card in hand, do action Y. We used this style of AI in our digitization of Ascension.

Despite being the dominant style of AI for shipped games, there are two main problems with this kind of technique. One, it doesn’t scale with new content. Every time expansions are added to the game, not only does new script need to be written, but also old script may become obsolete. Take the scenario where a particular mechanic is quite powerful in a game. A scripted AI might favor the use of that mechanic. If an expansion comes along that rebalances the game, undermining that mechanic, the original AI needs to be manually rescripted. In popular games with many expansions, this can become a gargantuan task and often as the game grows, its AI acumen diminishes. Two, the more complex this AI grows to be, the bramblier it is to debug as more and more conditions are layered into a decision. It's also more likely to have expensive evaluations hidden in the codebase that slow the game down.
Reinforcement Learning
For our next project, Race for the Galaxy, we scrapped our utility AI code, and instead integrated, for the first time, a neural network into a shipping card game.

The neural network has inputs that describe the state of the game. How many players are there? What expansion content is in play? How many points does an opponent have? What cards are in the discard pile? And so on… These inputs contain the facts the AI needs to make its decision regarding what actions to take. If an expansion adds new content to the game, the developer needs simply to add additional input nodes corresponding to the new content, then run additional training rounds. These automated training rounds rebalance how much weight is given to a particular strategy given the new facts of the game. Literally, that’s what the AI is doing. It's adjusting weights between the input, hidden, and output nodes of the network to optimize the output nodes that score highest for moves shown likely to result in a win during training.
Knowledge-free learning is an ideal tool for developing a game AI that needs to be adaptably good at accommodating new expansion content. Typically neural networks learn by studying training data. You feed your network a bunch of pictures of cats, these are the training data. Then ask it, is this new picture a cat? Training data is expensive and labor intensive to produce, creating a scaling problem for games that are trying to evaluate not whether something is a cat, but whether an entire strategy is viable. Knowledge-free learning eschews training data. The AI can play the game against itself, and then get the result: Did I win? That information is like the training image of a cat. It can use its accumulation of Did-I-wins to ask: Is this new thing likely to result in a win? Turns out, it works well and we have moved all of our boardgame AIs to use knowledge-free networks.
How Does the Neural Network Work?
The goal of the network is to be able to, for every possible turn in the game, feed in information about the current state of the game, and get out information about whether a move is likely to result in a win. During each turn, the AI will consider several different moves it can take. Each of these moves is simulated into the future using the existing game logic. For each possible move, the AI runs this simulated-forward game state through the network comparing the outputs of all moves. Whichever move resulted in the highest output score for itself determines the move the AI will take in the game. The flow is pretty simple. First the developer designs the shape of a neural network.
Network structure
The neural network has three layers. First, the input nodes. The developer looks at a game and decides what data might be important facts. In a game like Dominion, this might be, “There are four players,” “There is one remaining Duchy,” “I have five coins,” and “The game is ending soon.” (It helps to have played the game a bunch!) These become the input nodes.

Technically speaking these inputs are actually represented as values from 0.0 to 1.0. The numbers are run through a function to take them from their natural form to the range the network can work with.
Second is a layer of hidden nodes. These are arbitrary and don’t need to be defined – the neural network figures out what to do with them automatically.

Third, output nodes yield a score from zero to one. There is one output node for each player, so we have four outputs in a four player game. The output of the network tells us how “good” a move is for all players. The closer the output for a player is to one, the more likely it is to result in a win for that player. The output will be used to predict which among many moves is most likely to move an AI closer to victory. You can understand how on turn one, the outputs in a four player game are likely to be .25 across the board, because each player has an equal shot at winning. Toward the end of the game, the outputs may look more like .925, .025, .025, .025 because one player is running away with the game. Throughout the game, the AI will always choose the action that will result in the output score for itself getting closer to one hundred percent chance of winning.

The three sets of nodes fit together as depicted in the image below. Each node is connected by a weighted line. To begin with, these edge weights start with arbitrary numbers. Over time the edge weights will be adjusted by an algorithm which enables the network to become more and more predictively accurate.

Decision making
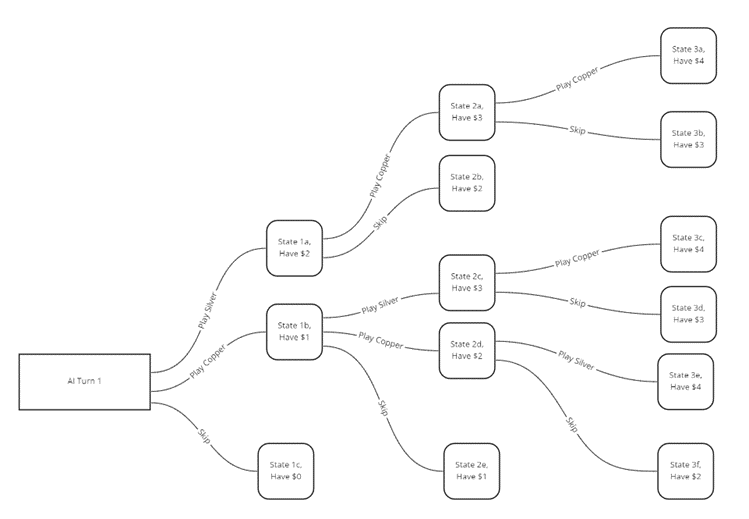
On turn one, the AI player reviews what possible actions they could take. They build a tree of possibilities based on their understanding of the game rules. This building of a tree is called the simulation. Say the AI player has two Coppers and a Silver in their hand. They could play a Silver, a Copper, or skip. Either of these three options will lead to a new future game state.

If the AI player skips, they may reach the end of their turn. State 1C is terminal. But if they chose to play a Copper, they have another choice. They might choose to play a second Copper. And so on. This following tree shows all possible states they could wind up in, based on their decisions with just these three cards. In any given turn, there may be many more possible decisions. You can imagine a tree of all possible decisions the AI player could make until the end of their turn would be pretty big!

The terminal nodes on the tree are the game states the neural network processes as its input. The node comprises the entire game state. Each terminal node is run through the network, and the one that yields the highest score for the AI player determines the decision the AI makes.

Learning
You see how the AI makes a good move based on the neural network, but that assumes the network is giving accurate predictions of what will be the end result. How do you get a network to give accurate results?
Accurate results come from having the right weights. We can get the right weights by training the neural network. The unique thing about our neural network is that it is “knowledge free.” This means the AI starts out very dumb, and learns over time simply by playing and finding out what worked. The neural network knows what worked by getting a feedback signal. This comes at the end of the game, did it win or not? But there is also a clever trick called temporal difference learning. The AI not only waits until the end of the game to get this feedback signal, but also, on a turn, uses the neural network to see if its action is predicted to result in a win, and it uses that prediction as a feedback signal. It’s not quite as accurate, but it gets better with every crank of the knob. To adjust the edge weights from turn to turn, we plug the outputs of our prediction into a formula like this:

The formula provides us with information regarding how much to adjust the edge weights of the neural network based on the outputs received.

That means that for every turn the AI takes in the game it will adjust the neural network as it goes. Without the temporal difference technique, it wouldn’t be feasible to train a network like this in a reasonable timeframe. Once the edge weights have been honed through training, a static version of the network is included in the shipping product, and the AI continues to call the network to determine its best move.
We first used this technique in Race for the Galaxy. This game's AI was trained in over thirty thousand games, with weight adjustments at each time-step. We achieved a ninety-seven percent win rate. Having a high win rate offers replayability value even for advanced players, and can easily be nerfed to softly challenge newer players.
Boardgame apps work best by offering a variety of AI difficulty levels, allowing players to advance up to the most challenging experience at their own pace. The technique described so far is what we used for our Hard AI. To create an Easy or Medium AI, we introduce noise to the output score. After adding noise, the new highest scoring move may differ from the originally recommended move, resulting in suboptimal play. We can tune the amount of noise added, adding more noise for an even easier AI opponent.
Given the success of this research-project-turned-shipping-feature, we wanted to see if we could apply a similar technique for Dominion.

Roadblocks
Something that’s been glossed over a bit is that in Race for the Galaxy we created two neural networks. The ‘Win Probability Network’ is described above. The ‘Opponent Action Prediction’ network is a similar network that guesses what opponents will do using outputs to predict their moves. This guess is helpful in more accurately simulating the game state. Further, a new flavor of each of these networks is specialized for different game configurations. Is it a two player game? Are all expansions included? Each of these answers leads to a different set of networks, each taking up a chunk of our download budget. Using a specialized network delivers better results, but at a cost. We shipped with twenty four individual neural networks to manage the AI. Because Race for the Galaxy ships on phones which have limited download capacity, we wouldn’t want to add too many more of these.

A Bigger Scope
While Race for the Galaxy has five expansions, our next game, Dominion, has a daunting fifteen. The larger scope means our Race AI solution wouldn’t scale for Dominion in three ways.
One, creating additional specialized networks to accommodate all of the different permutations of card sets across fifteen expansions would exceed the network size budget in our downloadable.
Two, Dominion with its expansions has over five hundred cards, which is hundreds more than Race. These would require thousands more input nodes, exploding the size of individual networks, due to the fact that for each card in the game there is an input for each possible place it could be. For example, is card X in the discard pile? True. That’s an input. Is card X in the player’s hand? False. And so on. Because of this, each card adds ten to twenty new nodes.
Three, because of the larger scope of the game, there are many more possible decisions to train for, which would require even more computing resources to train.
Longer Term Thinking
The biggest problem of all is that, in Race, you can do very well by just optimizing how you play each turn. You don't need to think too much about your long term strategy because of the randomness of card draw. The Race AI can get away with only looking one turn into the future. In Dominion, that’s not the case at all. The game is all about figuring out and executing a long term strategy. A one-turn lookahead isn’t nearly enough. We would need a new model that efficiently looks deeper into the future.
To solve these problems, we’ve waded into the uncharted territory of applying techniques behind the Alpha Zero research project to create a neural network AI for a shipping game.
Adding Alpha Zero Techniques
If you remember our simulated search tree, we looked at all possible actions that could be taken as part of making a single turn.
In Race for the Galaxy, it worked well to run the game state through the network at the end of one simulated turn.

Unfortunately, that was a particular luxury based on Race’s design. Race has a lot of randomness and the player needs to adjust their strategy nearly every turn in reaction to the new cards they’re working with. In fact, keeping loyally to one strategy throughout the game is many a new player’s folly.
Deeper Look Ahead
In contrast, players of Dominion often figure out their entire strategy BEFORE the game even begins. Because you’re working with a set of ten known card piles throughout the entire game, there is less need to pivot based on new information. For example, a player may see the card Gardens in the Kingdom. (A Kingdom is the subset of cards available in a particular game.) Gardens grant Victory based on accumulating many, many cards over the course of the game. The strategy is overarching; decisions shouldn’t be made locally on a turn by turn basis. Overall the player should focus their entire strategy around amassing a large set of cards by focusing on abilities with extra buys, gainers, and cheap cards that mill through junk. This takes a strategic commitment. A search tree that only simulated one turn ahead couldn’t achieve overarching strategic success.
Go and Chess Exhaustive Search
The only option for Dominion is to simulate much further ahead. Classic neural network AI solutions for chess and Go simulate twenty or more turns into the future. In chess and Go, while there is only one decision per turn, there are hundreds of possible moves for each game state. For example Go has almost four hundred moves per game state. Your search tree quickly amasses billions upon billions of nodes.
Monte Carlo Tree Search
If a game requires deep lookahead, but building an exhaustive tree is not performant, a Monte Carlo Tree Search (MCTS) can be used to randomly build the tree. Instead of building every branch, a random weight is assigned to each existing branch. The algorithm identifies the branch with the highest weight, and only builds from there. What this gets us is a much deeper tree, without it being so fleshed out. It gives us access to overarching strategies that carry across many turns, without blowing the performance budget.

Hand Authored Search Tree
Taking it a step further, rather than randomly determining the weights, you can use the developer’s knowledge of the game to manually direct how the tree grows. Take for example our game Roll for the Galaxy. This is a dice game, which means we can benefit from some handy dice-probability math to know that some branches of the search tree are much less useful to explore. For example, there may be a branch where you explore the possibility of all fifteen dice rolled landing on the same face. This is highly unlikely, so it’s advised to ignore this branch and focus on more likely scenarios. We can rule out less likely scenarios, while still achieving a deeper lookahead. The result is a much narrower, much deeper tree.
Pitfalls of Authoring
However, hand pruning the search tree has the same pitfalls as hand authoring an entire AI. One, it doesn’t scale to future expansions. Two, our choices may become obsolete with new content. And three, the network’s efficacy is constrained by the developer’s skill with the game itself.
AlphaZero
If we want to avoid the pitfalls of hand-authoring our tree, MCTS is pretty good. It gets deep into the simulation. But there is a problem. What if one of the randomly low-weighted branches was actually representative of a REALLY good move? The AI won’t know about this move because it won’t have a chance to run its simulated game state through the neural network to discover how good it is. The consequence is that a skilled player may easily beat this AI, and set the game down because it’s too easy.
AlphaGo, a project by Google’s DeepMind, introduced a helpful innovation. Rather than building out this tree using random weights as with MCTS, it used the neural network itself to determine where to search. So, this new neural network provides two things. Like before, it still says how likely a player is to win in a given state. This is expressed as a list of values, one for each player. The highest value showing who the move benefits most. Unlike before, the output also provides an update to the weights for which branches to explore next. This is also expressed as a list of values corresponding to the number of choices a player could make at a given juncture. What would this look like in Dominion? If a player plays Workshop, they can gain a card costing up to four. If there are six such four-or-less cost cards in the game, there are six possible branches off of this tree to explore. The outputs include six new weights, each representing how valuable the AI predicts that branch is to explore.
Performance Risk
The technique behind AlphaZero was only proven to be effective in an artificial scenario: one with internal access to Google’s supercomputers to process the training and to search the tree. It had never before applied in a commercial product, and there was no guarantee it would work. It was proving to be unrealistic for a project in production with time and processing limitations. Applying the technique from AlphaZero was a looming performance risk.
The Breakthrough: An Embedding Layer

To understand our solution to make this performantly viable, it helps to understand a bit of the game. Dominion is a deckbuilder and every turn you may buy a new card to strengthen your deck. Say you want to know what a good card to buy is. How do you choose? In our games prior to Dominion, the network has a concept of each card individually. It knows if a card is weak or strong, cheap or expensive, good early or better late game. And that’s great! We didn’t even have to hand-script this knowledge, the AI learned it through self-play. You can see in our debug text in Shards of Infinity, the green display shows the AI rates buying this card fairly low at this moment of the game. Knowing each card individually is OK for a game with a small number of cards, but in Dominion, with nearly six hundred cards and counting, there are too many cards to process in this way.

Dominion has fifteen expansions, over five hundred cards, of which you choose ten each time to form a Kingdom to play with. This leads to over sixty-six sextillion permutations of possible Kingdoms. A neural network is only able to effectively tell you how good a move would be given a set of input if it has built a familiarity with that input. Basically, the neural network is making a function of all of the inputs to generate outputs with the caveat that the network has been shown any particular combination in the past. But with this many permutations of Kingdoms, we don’t have the processing power to learn all of these. So figuring out whether a particular card would be good to buy given any possible Kingdom is a fairly impossible task under the limitations on modern processing power.
So what else could we do? We have a new advancement in Dominion we haven’t used in prior games. We added an embedding layer, which revolutionized our network.
Rather than our neural network understanding each card in the game as one unique input, the embedding layer is a layer of nodes that is designed to understand the composite, standard elements of a card. For example, the card’s cost, its Victory value, or how many ‘Buys’ it grants. These make up the “DNA” of the card.

Each card is basically a different combination of these components, such as ‘draw more cards’ or ‘get an extra buy.’ Determining value based on these modular components is particularly valuable because in Dominion a card may not be very powerful on its own, but in combination with another card, it can be quite powerful. One example is the Smithy and the Village. A Smithy lets you draw three cards. On its own it’s OK, but if you draw into more Action cards, they’re basically wasted. And Village is OK.You can draw a new card, and it gives you two actions, so hopefully you have another Action card… but together they’re a great combo! So we want a way to determine the value of any card based on its components, such as +Cards, or +Actions, given what other cards we already have. How do we do this?
One Dimensional Classification
We’re talking about a boardgame here, so it’s a good assumption that cards are relatively balanced. Cost wise, expensive cards are generally better than cheap ones. We can line the cards up on this one dimensional graph from lowest to highest costing cards. So we can start by saying, it’s probably better to buy a higher cost card. Generally that’s true, so yes, buying a Gold here, costing six, is generally much better than choosing to buy a Copper, which costs zero.

Two Dimensional Classification
However, it may be that there is another rationale when choosing cards to purchase, such as having a couple Smithies in your deck. In Dominion, you can only play one Action card per turn, so if you drew multiple Smithies into a hand, any more than one is wasted. To address this, we can add a second dimension to our graph. This dimension is the number of additional Actions a card lets you play. That way, if you draw more than one Action card, you may be able to play all of them. So now we have two axes toward determining the best card to buy. This is multidimensional classification.
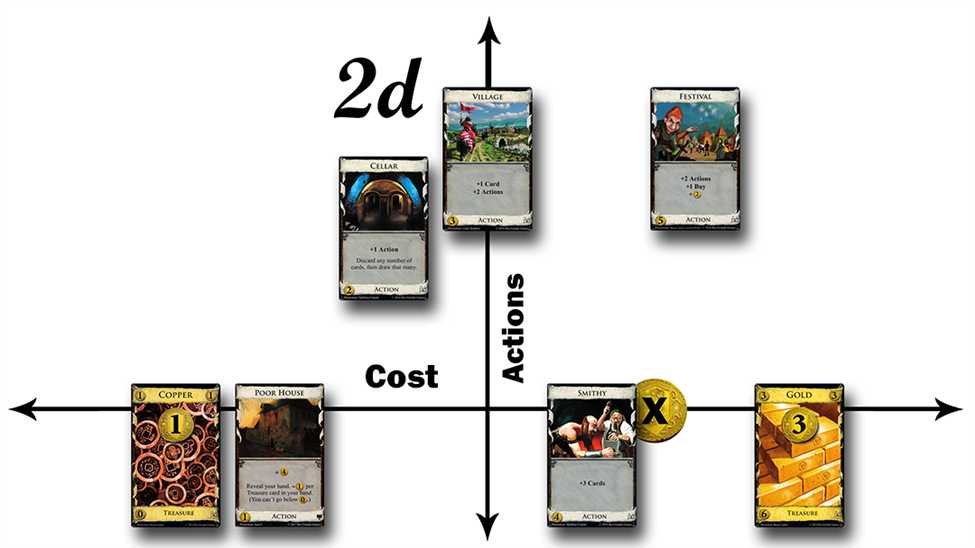
Once you’re using two dimensions, you can look for the card that is most expensive AND gives the most additional actions. In this case it’s the Festival. So that would be the “best” card to buy. And inversely, we can assume that Copper, at a cost of zero, providing zero additional actions, is the worst card to buy.
Adding Dimensions to the Network
To include these dimensions in the framework of the neural network, we can add each new dimension as a node of an embedding layer. Our network now has a subset of nodes for accommodating the DNA components of a card. Since all cards share a small subset of components, the network size is greatly reduced, even though it handles all cards including many of those designed in the future - as long as they use existing mechanics.

D Dimensional Classification
You can add many more dimensions and create a D-dimensional graph. So here we have added an extra dimension, and that is “card draw.” Our dimensions are still X Cost, Y Actions, and now Z Card Draw. In our input layer, each of the nodes at the top here represent cards you could buy, and Village is one of them. In this example we’re using a 3D embedding.

If you were to hand author the embedding layer, you could decide what the nodes would relate to. So for example, Village could have an edge weight of three for cost, two for Actions, and one for card draw. We can use this tuple to evaluate how good it would be to buy the card Village.
In reality, in our final product, we as developers don’t actually have to define what those axes are. The neural network determines the meaning of the nodes, which means it can learn beyond a semantic level.
Skill Beyond Semantics
If we have a lot of Smithies in our deck, and we want a card that provides additional Actions so we can use them, a traditional utility approach might be to look for a card that says “+X Actions.” That uses the semantic keyword on the cards to make a recommendation. But the card Kings Court doesn’t include this keyword, so it might be missed. However, the neural network can learn by playing the game that Kings Court effectively adds space to play more Action cards.

Latent Meaning
Adding the embedding layer lets the neural network learn the latent features of the cards, such as whether they provide more Actions. Embeddings map these cards to real vectors so that similar cards are close to each other. Here, the King's Court, and the Festival are quite close to each other, both being expensive cards that provide more Action play. The nice thing is, you don’t need to train this separately, the embedding layer lives right in your main neural network.

Non Authored
You don’t need to tell the embedding layer what dimensions to evaluate. Which also means that the neural network can come up with dimensions that might be beyond our skill level as a player to identify. What does it arrive at? Well, it’s a bit of a black box, although with some analysis we could probably figure out what a particular node is mapped to. Moreover, you don’t need to tell the network what the constituent components of the cards are either. Each card is opaque to the network for the most part, but in training it is able to determine the features of the card because those features affect the outcome of the game. So, two similar cards would affect the outcomes similarly, and would end up having similar embedded features.
Compressed Networks
In fact, because of the embedding layer, we don’t need to ship with as many different neural networks, like we have with previous titles, such as Race for the Galaxy. Race for the Galaxy’s twenty-four neural networks are each tailored to a particular expansion set and number of players. This allows us to tailor each network’s inputs by removing inputs that do not apply. Removing unneeded inputs, and the weights associated with them, improve training speed. Additionally, it is expected that optimal strategies differ in these situations, especially as expansions are added. Older cards that may be weak in the base game may become stronger as they combine with cards introduced in later expansions. Tactics that may be strong in two-player games may not fare as well in larger player counts. Training each of these independently allows the networks to specialize and learn the subtleties that may be missed in a single, overarching network.
With Dominion, two networks can now handle all the cards with the help of the embedding layer. We use one to specialize in two player games, and one to handle three player and higher games. The embedding layer compresses thousands of input nodes (cards in locations) down to ten (embedding nodes) characteristics, which is a huge efficiency gain. This is great because we can have a situation in our training where we never see a Kingdom including Village, Witch and Smithy. So the neural network wouldn’t learn how to use these cards together, but with our model we will have tested a game that uses the constituent components, +Actions, +Curse, + Cards together. This allows us to better guarantee that all card combinations will be trained against.
Additional Innovations: Capitalizing on Player Symmetry

On top of the embedding layer, and AlphaZero style tree search we have come up with a few more tricks to make an AI like this possible to run on everyday users devices. We can identify symmetries in our input to avoid having to train the same data multiple times. For Roll, we first took advantage of the symmetry between players and unified the weights for the player specific inputs. This means that rather than training to learn the value of having a card in hand for player one, and then training again to learn this value for player two, we can assume the value is the same. This is both valuable performance-wise during training and also during evaluations made using the neural network.
Duplicate Card Symmetry
The savings with symmetries can be applied to more than just player input. In Race and Roll for the Galaxy, almost every card is unique, and there’s a rule that prevents players from playing duplicates. But in Shards of Infinity, our next game, card duplicates are common. We can use the same concept of symmetry to speed along training by treating duplicate cards identically.

Results
With our new method we are able to simulate one thousand steps into the future on current phones, which means overarching strategies are being discovered and used by the AI. The win rate of our AI is over eighty percent. Players are being challenged daily throughout the Dominion beta, in production on humble mobile devices.
The most interesting thing about this method is that our same AI that handled two-hundred cards at the start of development now handles five-hundred cards at the same skill level. These new cards were released via expansion packs created by the game's designer. Because of this, we have the confidence to believe that it will similarly handle new cards released in the future. To add new cards to our system, we do a bit of work to encode new mechanics, such as Traits in the Plunder expansion, but other than that, we just retrain. With a traditional hand-scripted AI, even with gutting and rewriting the full AI for every expansion, we would not have the confidence that the AI quality or speed would maintain itself over time.
An additional bonus is that the AI still functions well with new cards, even prior to retraining. This is especially helpful for testing the game as new cards come in. The game doesn't break and the AI has some sense of the new cards' value and strategy especially if they use previously known mechanics.
We're very happy with the results, look forward to Dominion's release, and are hoping other game teams consider adopting this technique.


--Theresa Duringer
CEO, Temple Gates Games
Fantastic technical writeup, super accessible and extremely interesting! I feel that hobby tabletop game ai is largely unexplored, and when it is, it's usually behind closed doors and not shared, so really thanks so much for this look into how these work. Also, being among the early digital ascension players really made me appreciate the work that went into scenario scripting, way before the advent of modern and more accessible ai.
Fascinating article. Fun to be reminded of the AI classes I took back when I was in university. Also very interesting to see advances since then. Very impressive feat getting something akin to AlphaGo to run on phones, honestly. Definitely helps to have an experience AI programmer on your team by the sounds of it.
I've actually played the Dominion app and it's honestly pretty good so clearly the AI is working as intended.